从入门到入土?不,是精通!科技论文完全指南:如何写出一篇优秀的科技论文

相信看到这里的朋友,已经对一篇科研论文(Research Article)的基本结构相当熟悉了。科研工作者最常撰写的文章类型之一就是采用 IMRaD 模式 的研究论文,即包括以下几个部分:
- I – Introduction(引言)
- M – Methods(方法)
- R – Results(结果)
- A – Abstract(摘要)
- D – Discussion(讨论)
我将结合自己的经历,分享论文写作的一般流程。需要注意的是,论文的撰写顺序通常并不等同于其最终的排版结构。在科研实践中,写作往往是从已有的研究结果出发,逐步向前、向后延展的。
通常,在完成一段时间的实验或建模工作后,我们首先获得的是一组数据或研究结果。因此,写作往往是从 Results(结果) 开始,根据结果再去梳理并书写 Methods(方法),说明这些结果是如何得到的。随后撰写 Discussion(讨论),对结果进行分析和解释,进一步明确其意义与不足之处。
在此基础上,我们再回到前面,撰写 Introduction(引言),梳理研究背景、动机、已有工作与创新点。最后撰写 Abstract(摘要),对全文进行简洁总结。
因此,我们推荐的实际写作顺序如下:
| 论文结构(发表顺序) | 实际写作建议顺序 |
|---|---|
| Abstract | Results |
| Introduction | Methods |
| Methods | Discussion |
| Results | Introduction |
| Discussion | Abstract |
采用这种写作顺序,有助于围绕核心研究结果进行清晰、有逻辑的论文构建,同时避免“边写边想”的低效写作状态。
Abstract(摘要)
摘要作为论文的开头部分,是整篇文章的核心思想浓缩表达。从读者的角度来看,摘要往往是他们接触论文的第一段文字,因此其写作质量直接影响读者是否有兴趣继续阅读下去。
✏️ 写作建议
一个优秀的摘要应当做到清晰(clarity)、简洁(brevity)、明了(lucidity),为了达成以上三个目的,我们建议使用三段式来完成摘要的书写,这个结构能够准确传达研究的关键信息,通常可以遵循以下基本结构:
✅ 推荐结构模板
- 第一段:研究背景与现状(现存问题或研究空白)
- 第二段:研究方法或解决方案(本研究采用了什么方法、模型或思路)
- 第三段:主要结果与结论��(最终发现了什么,有哪些贡献或意义)
这样的写作框架不仅能够帮助读者迅速把握论文的研究重点,也为后续的引言和正文做好铺垫。
第一段:研究背景与现状(现存问题或研究空白)
首先是描述现状,在描述现状中一般采取先扬后抑,先肯定 XXX 技术已经取得了显著进展,再指出其仍存在的不足之处。这些不足应与我们后续研究所要解决的问题密切相关,才能确保第一段在逻辑上的连贯与必要性。在此基础上,我们还得简要介绍我们提出的模型,它跟其他模型的不同之处:
例如:
Sensor-based human activity recognition is now well developed, but there are still many challenges, such as insufficient accuracy in the identification of similar activities. To overcome this issue, we collect data during similar human activities using three-axis acceleration and gyroscope sensors. We developed a model capable of classifying similar activities of human behavior, and the effectiveness and generalization capabilities of this model are evaluated. Based on the standardization and normalization of data, we consider the inherent similarities of human activity behaviors by introducing the multi-layer classifier model.
第二段:研究方法或解决方案(本研究采用了什么方法、模型或思路)
紧接着应阐明本文所采用的研究方法。该部分没有严格的结构要求,但应以准确传达方法本质为首要目标,其次才考虑语言的简洁与凝练。在确保表达准确的前提下,力求用最直接的方式让读者理解所提出方法的核心思想与实施方式。
例如:
The first layer of the proposed model is a random forest model based on the XGBoost feature selection algorithm. In the second layer of this model, similar human activities are extracted by applying the kernel Fisher discriminant analysis (KFDA) with feature mapping. Then, the support vector machine (SVM) model is applied to classify similar human activities.
第三段:主要结果与结论(最终发现了什么,有哪些贡献或意义)
最后,我们需要介绍模型的实验结果,包括运行效率、性能表现和评估指标,并突出模型的优势。至此,整个摘要的内容就基本完成了。
例如:
Our model is experimentally evaluated, and it is also applied to four benchmark datasets: UCI DSA, UCI HAR, WISDM, and IM-WSHA. The experimental results demonstrate that the proposed approach achieves recognition accuracies of 97.69%, 97.92%, 98.12%, and 90.6%, indicating excellent recognition performance. Additionally, we performed K-fold cross-validation on the random forest model and utilized ROC curves for the SVM classifier to assess the model’s generalization ability. The results indicate that our multi-layer classifier model exhibits robust generalization capabilities.
Introduction(介绍)
“Introduction” 顾名思义,是整篇论文的开端,它不仅介绍研究背景与核心模型,更是作者站在专业视角,以通俗且严谨的语言引导读者理解全文核心思想的关键部分。尽管引言部分没有固定格式,但写作时仍应遵循一定的逻辑和结构,并结合不断练习和积累提升写作质量。一个好的 Introduction 能够帮助不了解你研究领域的读者,在短时间内把握论文的主题、研究意义以及你在其中的贡献。因此,Introduction 不是背景的堆砌,而是一个故事的开端。
✏️ 写作建议
-
多阅读优秀引言
初学者应多阅读同领域内高水平论文的引言部分,特别是顶会、顶刊文章中的表达方式、背景铺陈、研究动机、贡献总结等内容。 -
尝试写出“自己风格”的引言
在模仿中逐步探索出属于自己的语言风格和逻辑结构,目标是:即使读者对该研究领域并不熟悉,也能通过阅读你的 Introduction 快速掌握论�文的研究动机、背景问题与研究意义。 -
逻辑清晰、循序渐进
好的引言往往从 宏观背景 讲起,逐步聚焦至当前研究的具体问题,然后阐述已有工作的不足,最后说明你的工作解决了什么问题,有哪些贡献。 -
参考文献的使用
- 尽量引用 近三年内的研究成果,以确保你的研究立足于当前学术前沿;
- 只有在引用奠基性理论或方法时,才建议使用三年以上甚至更久的经典文献;
- 每一条引用都应起到支撑你论述的作用,而不是堆砌数量。
✅ 推荐结构模板
- 第一段:引入研究背景和领域发展现状;
- 第二段:指出当前研究的挑战、空白或未解决问题;
- 第三段:概述你的方法、思路或创新点;
- 第四段:简明扼要地总结本文的主要贡献。
第一段:引入研究背景和领域发展现状;
例如:
Human activity recognition (HAR) involves identifying various human behaviors through a series of observations of individuals and their surrounding environment [1]. HAR has been generally applied in many fields, such as security and surveillance [2], sports and fitness [3], industry and manufacturing [4], autonomous driving [5], and the references therein...
第二段:指出当前研究的挑战、空白或未解决问题;
例如:
However, a problem was identified where single-classification models can cause confusion when distinguishing similar activities, such as ascending stairs and descending stairs. In a study conducted by Jansi et al. [23], they utilized chaotic mapping to compress raw tri-axial accelerometer data and extracted 38 time-domain and frequency-domain features. These features included mean, standard deviation, root mean square, dominant frequency coefficient, spectral energy, and others. They achieved a recognition accuracy of 83.22% in human activity recognition...
第三段:概述你的方法、思路或创新点;
例如:
In this paper, we propose the XR-KS (detailed description is given in Section 2) design aimed at addressing the issue of confusion between similar activities. To address the issue of similar activity feature similarity, we propose an SVM classification approach that utilizes KFDA. This approach effectively categorizes similar activities. Additionally, we conducted classification experiments on four common benchmark datasets and performed detailed analyses on these datasets. We compared our model to mainstream classification models. Experimental results demonstrate that our model exhibits excellent classification performance...
第四段:简明扼要地总结本文的主要贡献。
例如:
The remaining sections of this paper are organized as follows: Section 2 provides a brief introduction to the work carried out in this paper, along with details about the dataset used. Section 3 conducts a basic data analysis and employs appropriate data preprocessing techniques. This section introduces our proposed approach for human motion, which is based on a multi-layer classifier. Section 4 presents the experimental setup, provides results for our proposed method on multiple datasets, and offers an analysis and discussion of these results. Finally, in Section 5, we will summarize the insights gathered from these experiments and outline future directions.
Methods (方法)
方法部分同样需要广泛参考同领域的文献,了解该领域在方法描述方面的写作规范与表达方式。通常建议先阐明整体研究框架与核心思路,再逐步展开每个关键步骤的具体实现细节,以保证结构清晰、内容完整,并符合通行的学术表达习惯。
✏️ 写��作建议
-
图文结合,提升可读性
建议采用流程图或原理示意图结合文字描述的方式,直观展示方法步骤与模型结构。这种方式有助于读者快速理解整体流程与技术路径,尤其是在方法较复杂时更显高效。例如,以下几幅图可用于概括方法框架或关键模块: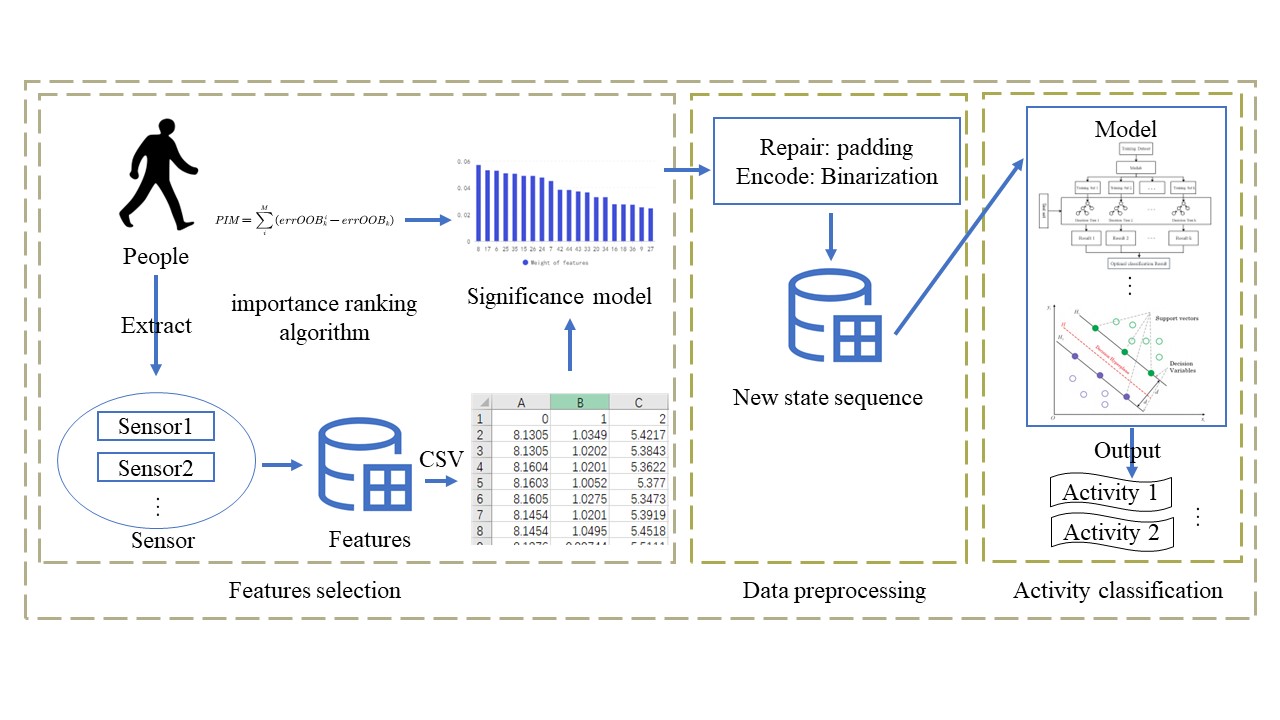
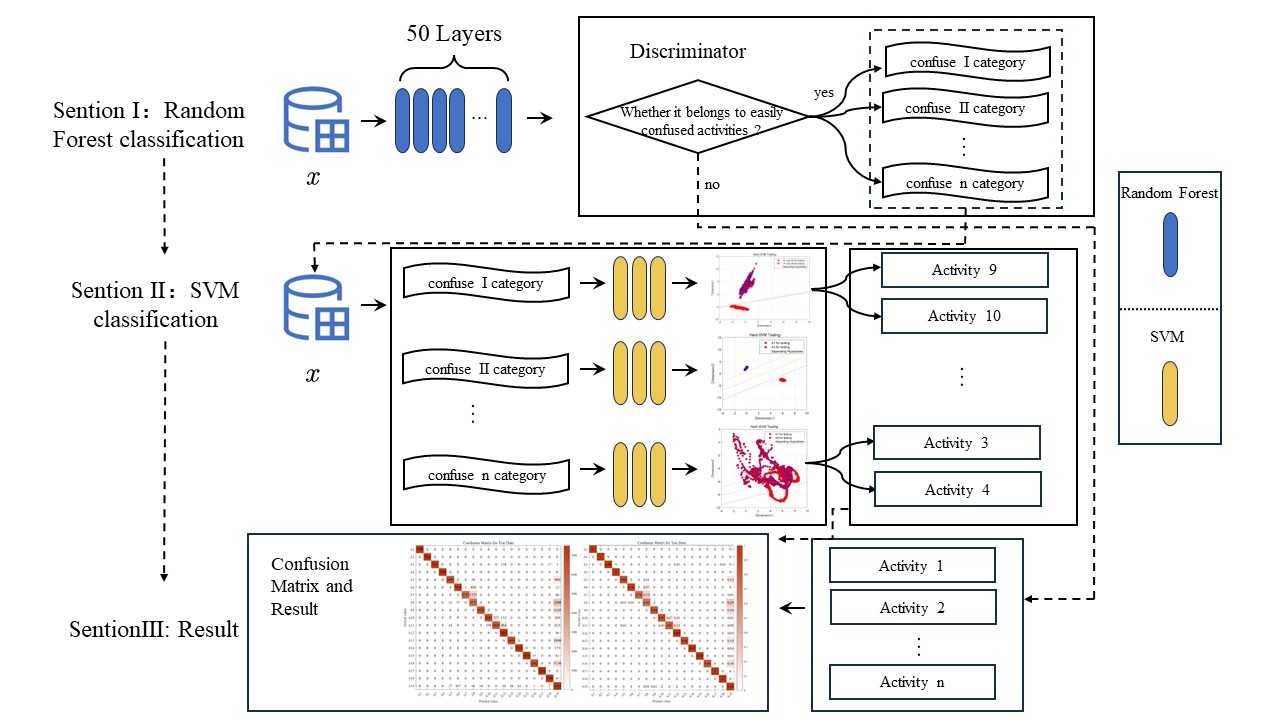
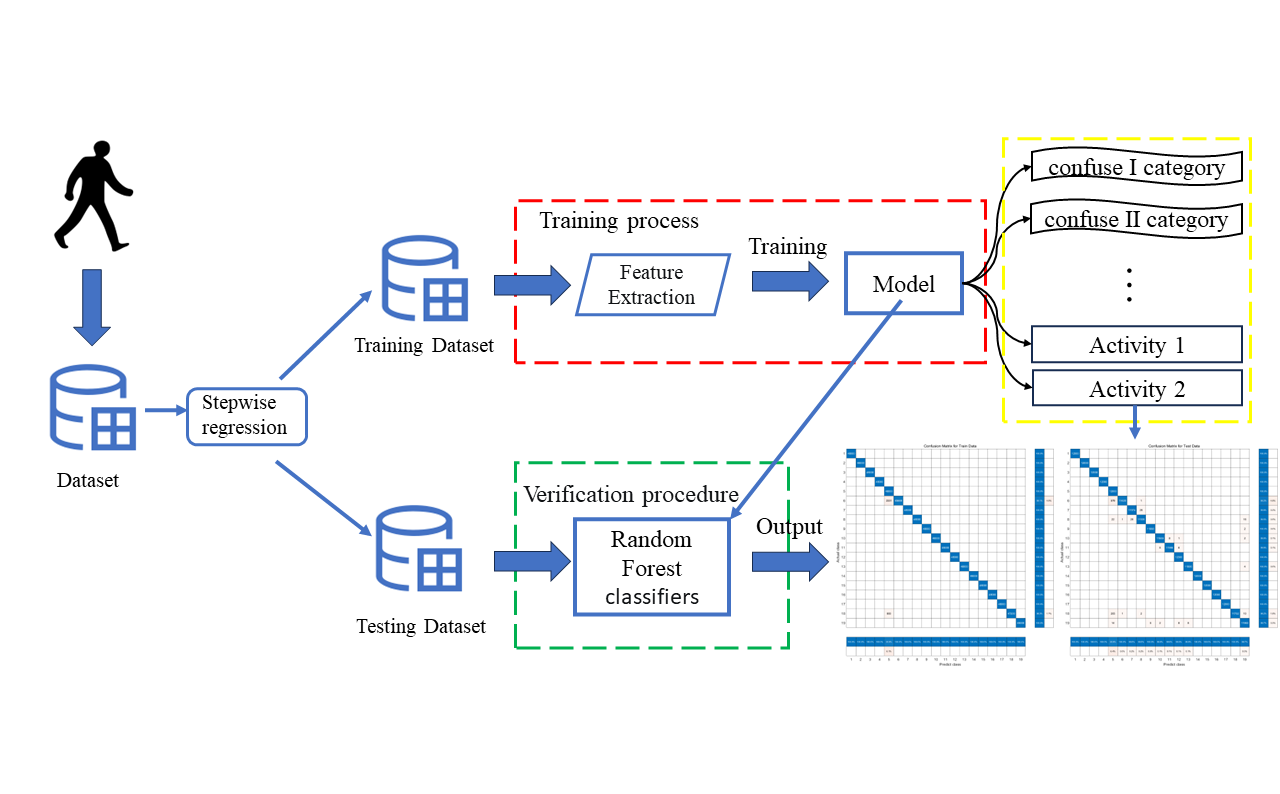
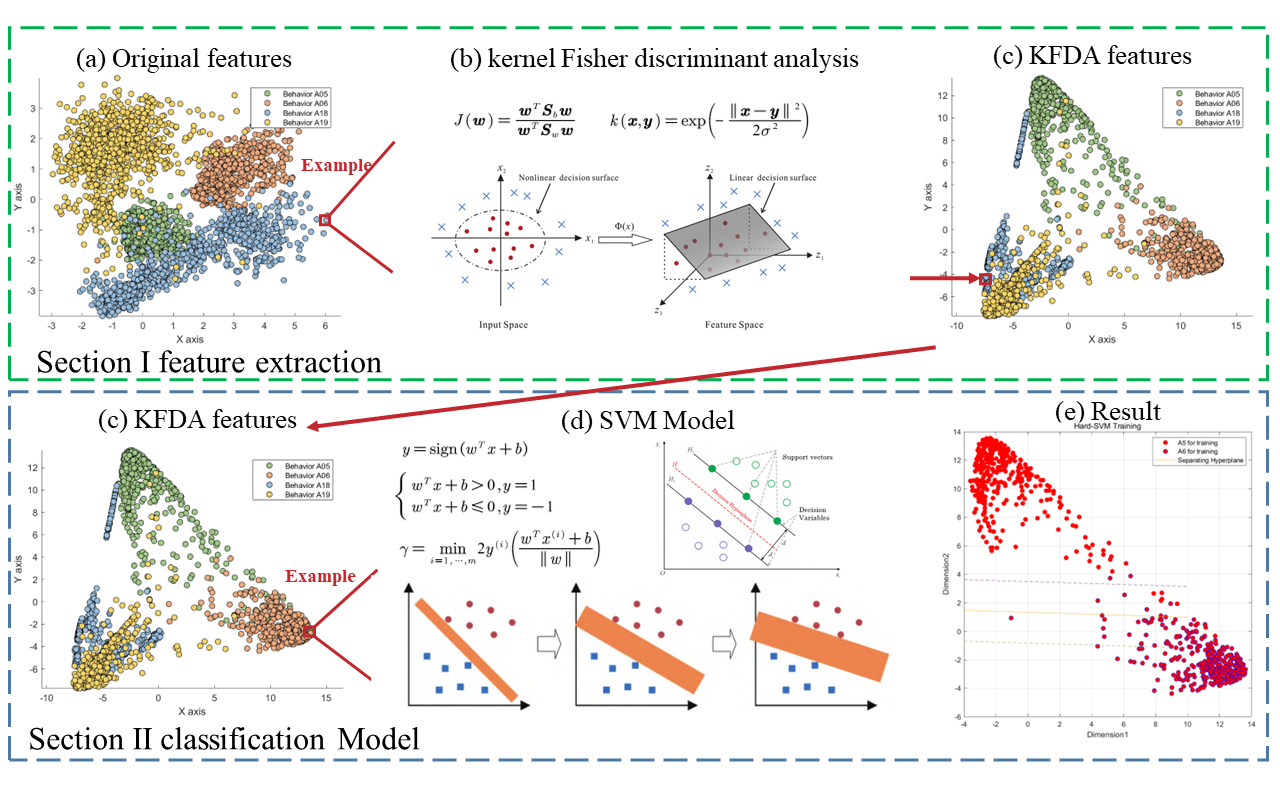
-
文字描述应遵循学术表达规范
撰写方法部分时,应参照领域内高水平论文的语言风格,特别是在术语使用、句式组织和逻辑推进方面。应重点突出方法的创新点及与已有研究的对比,避免空泛叙述或堆砌细节。 -
结构清晰,术语统一
建议将方法划分为多个子模块(如“整体框架”、“数据预处理”、“模型结构”、“训练策略”、“评估指标”等),使内容层次分明,便于读者逐步理解。确保关键术语前后一致,避免混用或歧义。
✅ 推荐结构模板
虽然方法部分没有唯一格式,但下面这种结构逻辑清晰、语言学术,适合作为写作参考:
3.3. Second-Layer SVM Classification Based on Kernel Fisher Discriminant Analysis
In Figure 6, we observe challenges in classifying actions such as ascending and descending stairs due to intricate details. Additionally, Figure 7 reveals that PCA and small intra-class distances in the original features hinder effective classification. To mitigate confusion between similar actions, we employ two key steps. First, we employ KFDA (kernel Fisher discriminant analysis) for feature dimensionality reduction to improve the discrimination of similar activities. This aims to increase the separation between distinct actions in the data space, thereby facilitating subsequent SVM classification. The workflow mirrors the one shown in Figure 8.
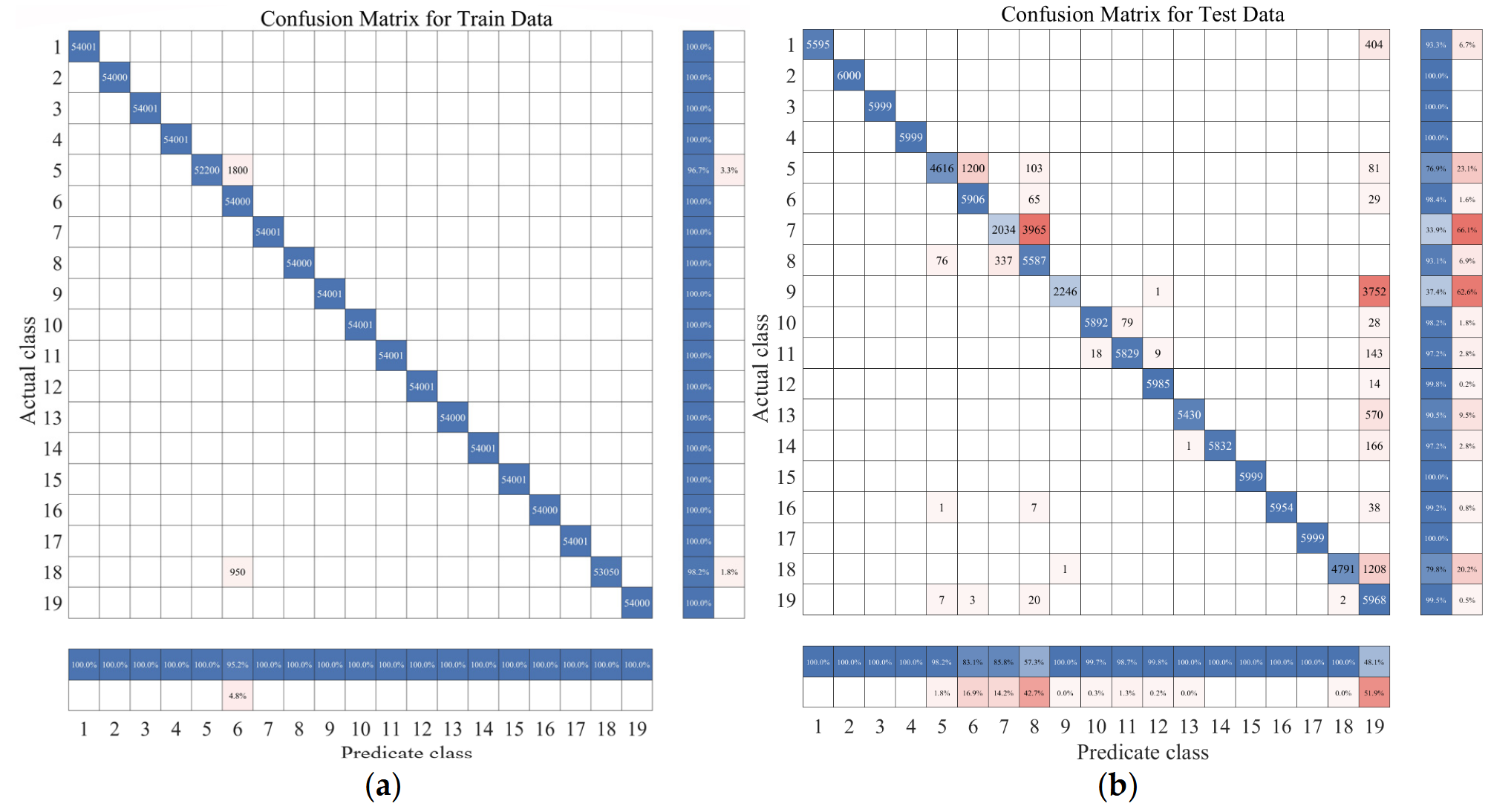 Figure 6. Confusion matrix of test set and training set random forest training. (The experimental setup is like the one in Figure 9). (a) Confusion matrix of random forest model by train set; (b) confusion matrix of random forest model by test set. (a) (b)
Figure 6. Confusion matrix of test set and training set random forest training. (The experimental setup is like the one in Figure 9). (a) Confusion matrix of random forest model by train set; (b) confusion matrix of random forest model by test set. (a) (b)
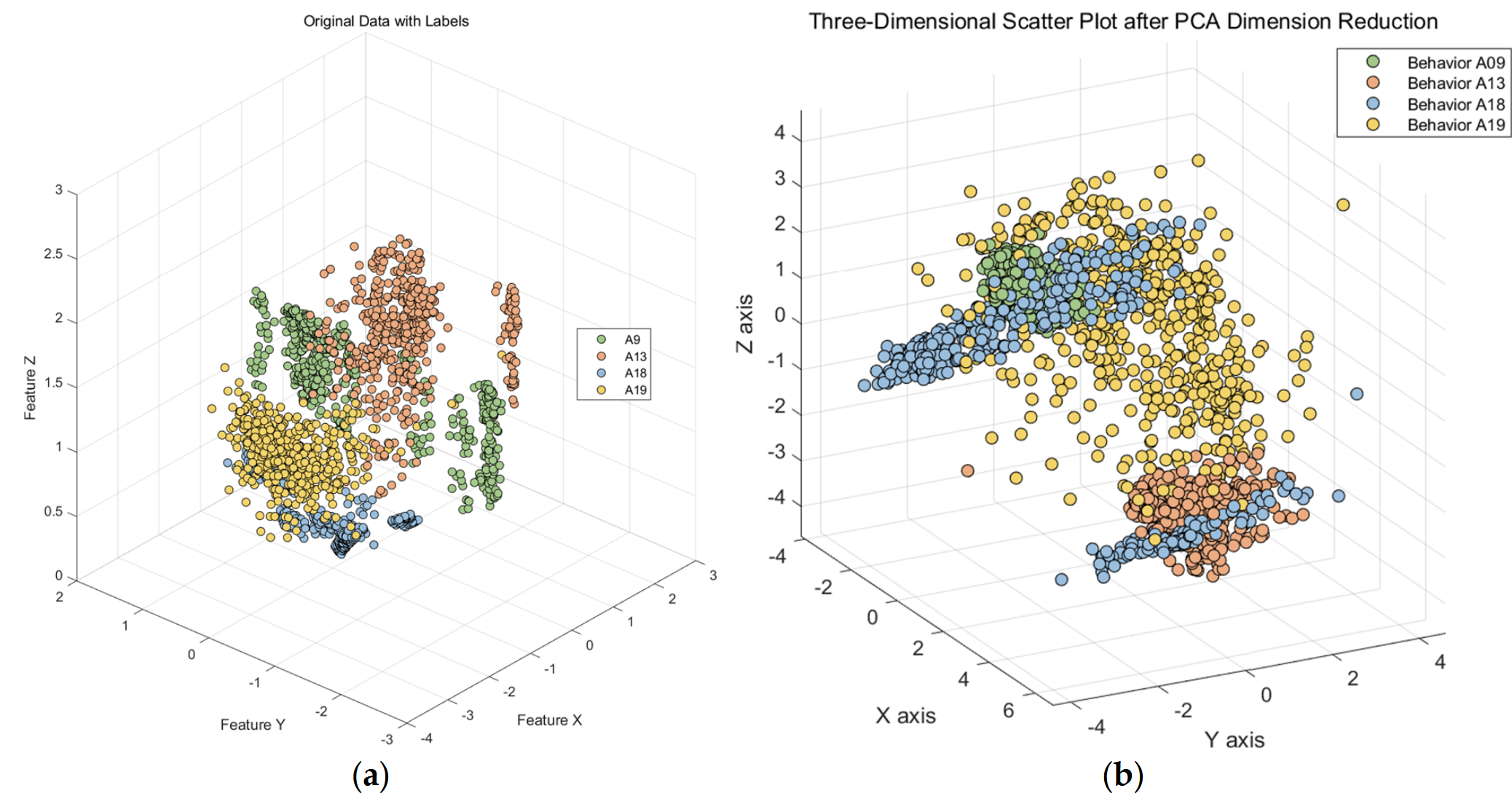 Figure 7. Primary feature and PCA feature. (a) Origin data; (b) data after PCA. Figure 6. Confusion matrix of test set and training set random forest training. (The experimental setup is like the one in Figure 9). (a) Confusion matrix of random forest model by train set; (b) confusion matrix of random forest model by test set.
Figure 7. Primary feature and PCA feature. (a) Origin data; (b) data after PCA. Figure 6. Confusion matrix of test set and training set random forest training. (The experimental setup is like the one in Figure 9). (a) Confusion matrix of random forest model by train set; (b) confusion matrix of random forest model by test set.
Figure 8. SVM model workflow based on kernel Fisher discriminant analysis.(The second-layer classification model ensures close proximity for (a) similar activities. (b) After applying KFDA, (c) 3 axial data and images are generated. (d) The two-dimensional data for the 2 axial image, (e) SVM classification, (f) the final results).
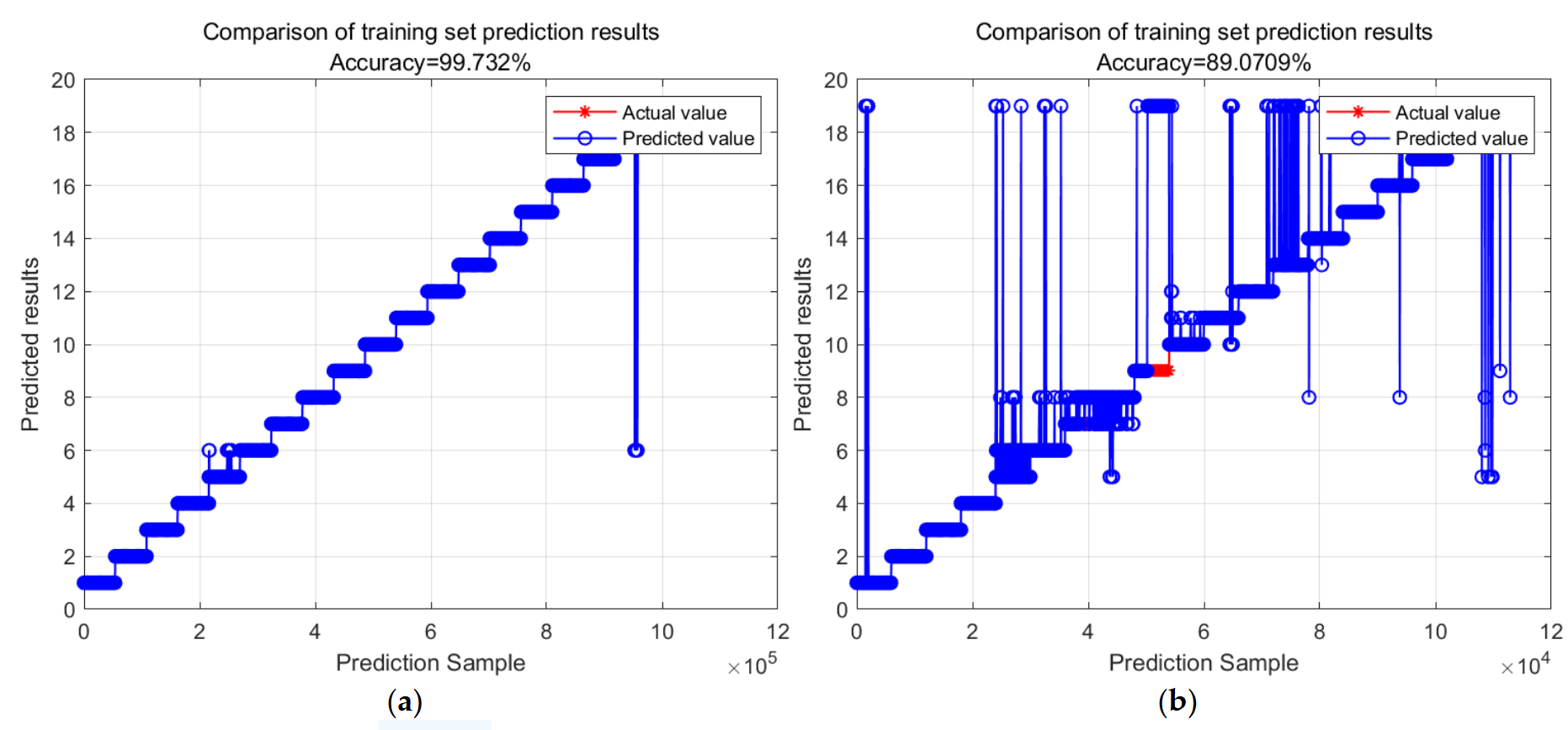 Figure 9. Comparison chart of random forest model recognition results. (The training and test set ratio was set to 9:1, and the experiment was repeated five times.) (a) Radom forest model by train set; (b) random forest model by test set.
Figure 9. Comparison chart of random forest model recognition results. (The training and test set ratio was set to 9:1, and the experiment was repeated five times.) (a) Radom forest model by train set; (b) random forest model by test set.
3.3.1. Principle of Kernel Fisher Discriminant Analysis KFDA is a pattern recognition and classification method based on kernel techniques and is an extension of Fisher discriminant analysis. KFDA is designed to handle nonline
...

📌 总结
从上例可以看出,高质量的方法部分通常包含以下几类图表:
- 流程图:展现整体方法流程或数据流动(如 Figure 8)
- 示意图:解释模型原理或结构(如 Figure 10)
- 实验图表:展示模型训练与测试结果(如 Figure 6, 9)
- 数据对比图:展示原始与处理后的数据差异(如 Figure 7)
- 伪代码/模块分解图:用于展示具体算法细节(Algorithm 2)
如果你发现你的方法描述中缺乏上述图类,建议补充相应内容,以增强论文的完整性与说服力。
Results (结果)
在结果或者说实验部分,我们的目标是呈现实验的主要发现,并通过文字对结果中出现的现象进行解释与分析。这不仅包括数据的对比与趋势的描述,更重要的是回答以下几个关键问题:结果说明了什么?是否验证了预期假设?又能得出哪些具有实际意义的结论?
为了撰写出高质量的结果分析段落,科研人员通常会使用一些在学术写作中约定俗成的表达方式和术语。这类语言不仅能增强论述的严谨性,也有助于在国际交流中保持清晰一致的表达。掌握这些“学术表达句式”的最佳方式之一,就是深入阅读本领域已发表的高水平论文,模仿其表述习惯与逻辑结构,并逐步内化为自己的写作能力。
✏️ 写作建议:如何撰写实验结果部分
-
清晰呈现结果,图表 + 文字结合更有效
在结果部分,应以图表为主、文字为辅,将核心实验结果直观展示出来。常见的图表包括折线图、柱状图、热力图、混淆矩阵、误差曲面图等。文字部分需要对图表进行说明,包括展示了哪些变量、反映了什么趋势或分布、��图中各元素所代表的含义等。应避免图表与正文内容割裂,确保图文能够相互补充、共同说明问题。 -
解释现象,避免只“复述图表”
文字描述不能仅停留在对图表内容的转述层面,而应进一步分析结果背后的成因和逻辑。即,在指出“发生了什么”的基础上,还要回答“为什么会这样”。这可能涉及模型设计对性能的影响、训练过程中的参数变化、数据本身的性质、实验设置的合理性等方面,从而体现出对实验现象的理解和掌控。 -
与预期结果或基线方法进行对比
结果分析不应孤立进行,而应将当前方法与已有方法或预期效果进行比较,突出改进点与优势所在。对比可以是定量的(如指标值差异),也可以是定性的(如鲁棒性、可解释性、泛化能力的提升等)。此外,还应注意说明比较的公平性,如是否使用了相同的数据集、参数设置是否一致等,以保证结论的可信度。 -
避免主观描述,尽量量化结论
实验结论应建立在客观数据的基础上,避免使用模糊或情绪化的语言,如“效果很好”、“显著提高”等。应优先使用具体指标(如准确率、召回率、F1 分数、RMSE、MAE 等)进行说明,并结合数值变化、提升幅度、统计显著性等方面展开分析。这样可以使结果更具说服力和可重复性。 -
总结关键发现,衔接讨论或结论部分
在结果部分结尾,建议对当前实验结果进行简要总结,提炼出关键发现,并为后续的讨论或结论部分做好铺垫。这可以包括确认某项假设是否成立、某种方法是否有效、某类特征是否起到了关键作用等,为整篇论文的逻辑闭环打下基础。
✅ 推荐结构模板
结果的第一部分应该简单介绍一下电脑所使用的硬件配置以及环境?使用了什么软件?,以确保实验具备可重复性和对比性。以下是常用的写作方式:
4.1. Experimental Setting
The experiments were conducted in Guilin, China, on an ASUS computer with the following specifications: an AMD Ryzen 7 4800H processor with Radeon graphics, operating at 2.90 GHz, 16 GB of RAM, and an NVIDIA GeForce GTX 1660 Ti graphics card. The operating system used was Windows 10. We used both MATLAB 2022R and Python 3.9.7 tools to conduct the experiments and validate them on four different datasets: UCI DSA, UCI HAR, WISDM, and UCI ADL. We also conducted a comprehensive evaluation of our approach. To maintain the conciseness of the paper, the following experiments are illustrated using the UCI DSA dataset as an example
与方法部分类似,结果部分同样建议图文结合,通过图表呈现实验数据,并配以恰当的文字说明,以增强论文的可读性与说服力。合理的图文搭配不仅有助于直观展示模型性能、对比实验效果,还能更加充分地呈现实验设计的严谨性与结论的可信度,是高质量论文的重要组成部分。
4.2. Extraction of Important Features
By utilizing the XGBoost feature value selection algorithm to analyze the 45 features in the dataset, we can evaluate the relative importance of each feature. As shown in Figure 14b, we obtained different experimental results by using the first n features as input to the first layer of the random forest model. These results effectively demonstrate the accuracy and time consumption in various scenarios. Therefore, we selected the first 31 features from Figure 14a to be used in the subsequent multi-layer classifier based on generalized discriminant analysis. To mitigate potential interference with our classification accuracy, we filter out features with lower importance.
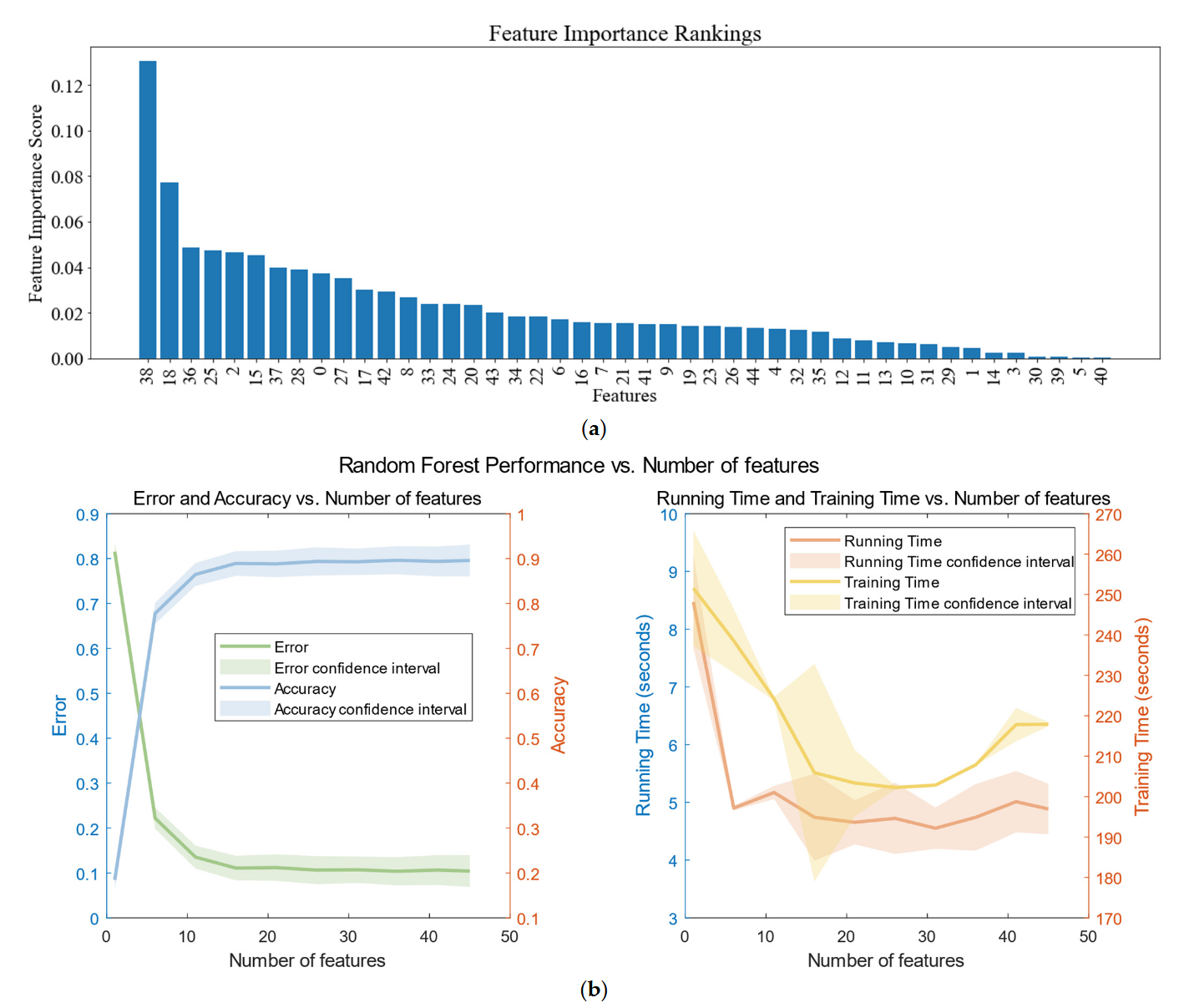
Figure 14. Weights of important features chart and effect of different numbers of features on a random model. (We set the number of features to be from 1 to 46 steps, took 5, and repeated the error experiment for each different n to obtain the mean and confidence interval.) (a) Result of the XGBoost feature value selection algorithm; (b) effect of different numbers of features on a random model.
Table 3. Number of features and error rate, accuracy rate, training times, and running time (mean ± std).

Discussion (讨论)
✅ 写作建议:Conclusion 或 Discussion 部分
在科技论文中,讨论(Discussion)或结论(Conclusion)部分主要用于对全文内容进行简要总结,并指出当前研究的局限性与未来的改进方向。
相比前文的方法、实验与结果部分,这一部分的撰写相对简洁,重点不在于再次重复技术细节,而在于:
- 提炼核心发现:简洁回顾研究所取得的主要成果和贡献;
- 反思研究不足:指出当前工作中的局限性,如实验设计的限制、模型适用性的范围等;
- 进行前瞻性展望:可以简要提出未来可能的研究方向、方法改进或应用拓展。
适当指出研究中存在的问题或限制,能够体现作者的客观态度与科学精神,也是高质量论文的重要标志之一。
✅ 推荐结构模板
5. Conclusion
In this paper, we proposed [简要说明你的方法/模型,例如:a multi-layer classifier model based on XGBoost and GDA] to address the problem of [研究目标或挑战,例如:recognizing similar human activities in sensor datasets]. Our approach was validated on multiple benchmark datasets, and the results demonstrate its effectiveness in terms of accuracy, robustness, and computational efficiency.
Despite these promising results, several limitations remain. First, [指出不足,例如:the model performance may degrade in the presence of noisy or missing sensor data]. Second, [例如:the generalizability of the model across different domains has not been extensively tested].
In future work, we plan to [展望,例如:explore domain adaptation techniques to improve cross-dataset performance, and investigate the integration of temporal sequence modeling]. These improvements are expected to further enhance the practical applicability of our approach in real-world scenarios.
总结
本文围绕 IMRaD 结构,系统介绍了科研论文的写作流程和要点。推荐先写结果,再补充方法、讨论,最后完成引言和摘要,以保证逻辑清晰、聚焦突出。
📌 欢迎关注 FEMATHS 小组与山海数模,持续学习更多数学建模与科研相关知识!
